What If Your AI Agent Could Actually Remember What It’s Doing?
A cognitive architecture that gives LLM agents structured, persistent situational awareness.
Every LLM agent has the same fundamental problem: it forgets everything between turns. Each API call starts from scratch. The model doesn’t know what it was trying to do, what just changed, what it should watch for, or what it tried before that didn’t work.
Most solutions treat this as a storage problem — stuff more context into the prompt, retrieve relevant chunks from a vector database, summarize the conversation. But that only answers “what does the agent know?” It doesn’t answer the harder questions: what is it trying to do? What just happened? What should it pay attention to?
SAGEN reframes this as a cognitive architecture problem. Instead of a flat memory buffer, it gives the agent six specialized modules — a structured representation of its current situation that gets updated every turn and injected as compact context.
Where RAG manages what the agent knows, SAGEN manages what the agent understands about its current situation.
Six Modules on a Shared Blackboard
All six modules read from and write to a shared state object called the AwarenessState. Each captures a different dimension of situational awareness.
A hierarchical tree of what the agent is trying to accomplish. Goals can be nested ("Learn Python" → "Understand list comprehensions"), have dependencies, and track their lifecycle: active, completed, blocked, abandoned, or deferred. Goals are inferred from behavior, not just explicit statements.
A timeline of what just happened — but not everything. Like human memory, routine events fade while failures, surprises, and pivots stick around. The module compresses history automatically, keeping a detailed window of recent events and sticky memories of consequential moments.
An entity-relationship graph of people, topics, concepts, and their connections. Crucially, it also tracks assumptions (things the agent believes but hasn't verified) and unknowns (questions the agent has identified but can't yet answer) — giving the agent explicit access to its own epistemic boundaries.
What can the agent do? What is it not allowed to do? What resources does it have left? The Self Model tracks capabilities, authority boundaries, resource budgets (token limits, API quotas), and a history of past failures with extracted lessons to avoid repeating mistakes.
A priority queue of threats, opportunities, anomalies, and transitions that need the agent's focus. Items have urgency scores and time-to-live values — they expire automatically when no longer relevant. The module also stores persistent scan patterns: things to always watch for, like topic shifts or emotional escalation.
The operational contract: communication style, output format, collaboration mode (autonomous, supervised, advisory), escalation rules, and hard constraints. This is the normative layer — not what the agent knows, but how it should act.
Observe → Update → Inject
Every turn, the same three-phase cycle runs to keep the agent’s awareness current.
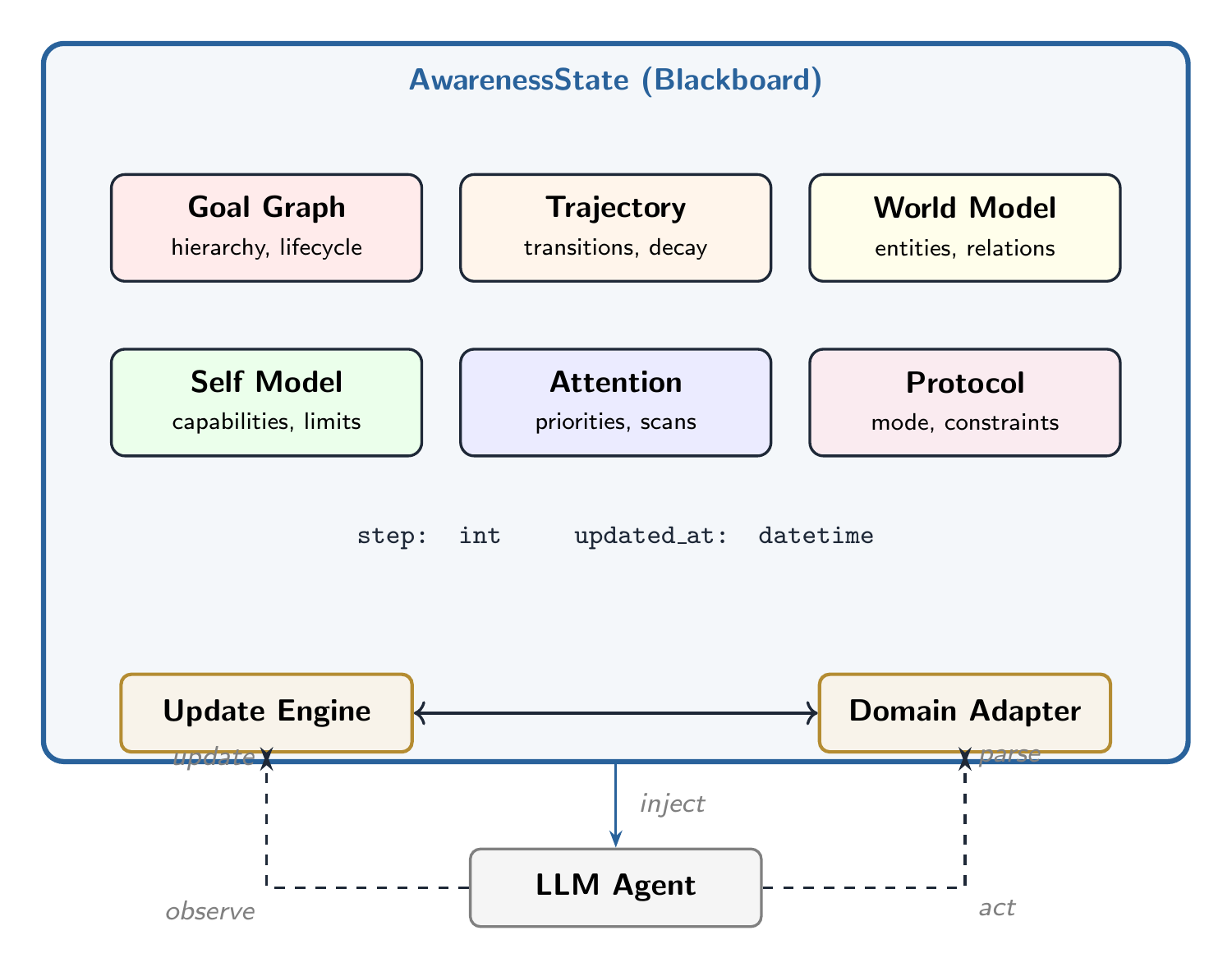
A Domain Adapter parses the raw input (a user message, a code change, a sensor reading) and extracts structured information: topics, entities, sentiment, goals, questions. This is the only domain-specific step — everything else is generic.
The engine applies the parsed observations to the blackboard: new entities get added, goals get spawned, attention items fire, trajectory events get recorded. Expired items are cleaned up. The global clock ticks forward.
The adapter renders the current state as a compact, prioritized text block — designed for insertion into the LLM's system prompt. Goals first, then attention items, then topics, then unknowns. Budget-aware: if the context window is tight, lower-priority information gets trimmed.
<sagen>
ACTIVE GOALS:
[explicit] Learn Python (p=0.7)
[explicit] Build a web scraper (p=0.7)
[inferred] Answer: What library for scraping? (p=0.6)
ATTENTION:
[opportunity] Callback to earlier topic
[transition] Topic shift: {'cooking'} -> {'Python'}
ACTIVE TOPICS: Python, web scraping
TRAJECTORY:
[progress] Continuing: {'Python', 'web scraping'}
[pivot] Pivoted from {'cooking'} to {'Python'}
</sagen>Test the Claims, Don’t Take Them
The reference implementation, ported to run in your browser. Step the documented conversation through the engine, watch the blackboard fill, and prove the serialization claim live. Then put a real model behind it.
Watch the blackboard accrue
The exact four-turn conversation from the paper, replayed through the in-browser port of the released engine. Step through it: the goals never get dropped on the pivot, the callback reconnects, frustration jumps to the top of attention, and the <sagen> block at the bottom is the literal context a SAGEN-aware model would receive.
“BeautifulSoup is not working! Errors everywhere!”
Frustration. A high-urgency threat item lands at the top of attention, so a SAGEN-aware reply can change its tone instead of diving straight into troubleshooting.
<sagen> ACTIVE GOALS: [explicit] Learn Python (p=0.7) [explicit] Build a web scraper (p=0.7) [explicit] Fix BeautifulSoup errors (p=0.7) [inferred] Answer: Can you help me learn Python? (p=0.6) [inferred] Answer: Good recipe for pasta carbonara? (p=0.6) [inferred] Answer: What library for scraping? (p=0.6) ATTENTION: [threat] User sentiment: frustrated [opportunity] Callback to earlier topic [opportunity] Callback to earlier topic [transition] Topic shift: web scraping -> cooking, pasta carbonara [transition] Topic shift: cooking, web scraping -> BeautifulSoup, Python, debugging ACTIVE TOPICS: Python, cooking, debugging, web scraping TRAJECTORY: [progress] Initial topics: Python, web scraping [pivot] Pivoted: web scraping -> cooking, pasta carbonara [progress] Continuing: Python, web scraping [pivot] Pivoted: cooking, web scraping -> BeautifulSoup, Python, debugging </sagen>
These counts are computed by the in-browser port as you step. The paper’s printed Table 5 reports 3 / 5 / 6 / 7 goals; the released code (and therefore this testbed) actually produces 3 / 4 / 5 / 6. The runnable artifact is authoritative — which is the entire point of being able to test a claim.
| Step | Event | Goals | Entities | Attn | Trajectory | Transition |
|---|---|---|---|---|---|---|
| 1 | Goal creation | 3 | 2 | 0 | 1 | progress |
| 2 | Topic pivot | 4 | 4 | 1 | 2 | pivot |
| 3 | Callback | 5 | 4 | 2 | 3 | progress |
| 4 | Frustration | 6 | 6 | 5 | 4 | pivot |
Checkpoint, restore, continue
The blackboard is the state, and the state is JSON. Run two turns, serialize to 2.5 KB, restore into a fresh engine, and run the last two. The result is identical, down to the byte, to running all four continuously — which is what makes a SAGEN agent durable across sessions, processes, and machines.
Same turn, with and without awareness
Type anything, or walk the four-message arc below (learn Python → pivot to pasta → callback → frustration). Each turn answers twice: once with a plain system prompt, once with the live <sagen> block added. Only the injection changes. The same model is asked the same thing; watch where awareness shows up.
Live model calls. Responses are not stored; the blackboard round-trips with your browser between turns.
From Stateless to Situationally Aware
Most agent frameworks bolt memory onto an LLM as an afterthought. SAGEN treats awareness as a first-class architectural concern. The result is an agent that knows what it’s doing, remembers what just changed, tracks what it should watch for, and understands its own capabilities and limits.
The adapter pattern means SAGEN works across domains. The same engine runs a conversational agent (tracking topics, emotions, callbacks) and a coding assistant (tracking errors, regressions, scope creep) without modification — you just swap the adapter.
And it’s open source. MIT licensed. The reference implementation includes a conversation adapter and a coding adapter, with full test coverage.