What If Your LLM Could Choose How to Think?
A paper about making constrained decoding faster by being smarter about which computation to skip.
When you ask an LLM to output JSON, or follow a grammar, or pick from a list of valid options, the model has to do something called constrained decoding. At every step, it scores every possible next token against the rules — even the ones that obviously don’t fit.
Imagine a classroom of 100,000 students. The teacher asks a question, and every single student raises their hand before the teacher checks who actually has the right answer. That’s dense decoding — thorough but wasteful.
LLM-QP asks: what if the teacher already knew which students might have the answer? Instead of checking all 100,000 hands, only check the 50 students who are actually eligible. And if the top student is way ahead of everyone else, maybe don’t even re-ask the question next time — just call on them again.
Three Tricks, One Framework
Instead of scoring all 100,000+ tokens in the vocabulary, only score the ones that are actually valid right now. If the grammar says only 50 tokens are legal at this step, why compute scores for the other 99,950? The paper proves these give identical outputs — you get the same answer either way.
If the model is very confident in its answer (the top choice is way ahead of the second place), maybe we don’t need to re-run the full transformer for the next token. The model’s internal state hasn’t changed much, so the answer is probably the same. Think of it like not re-reading the whole textbook for every quiz question when you already know the chapter.
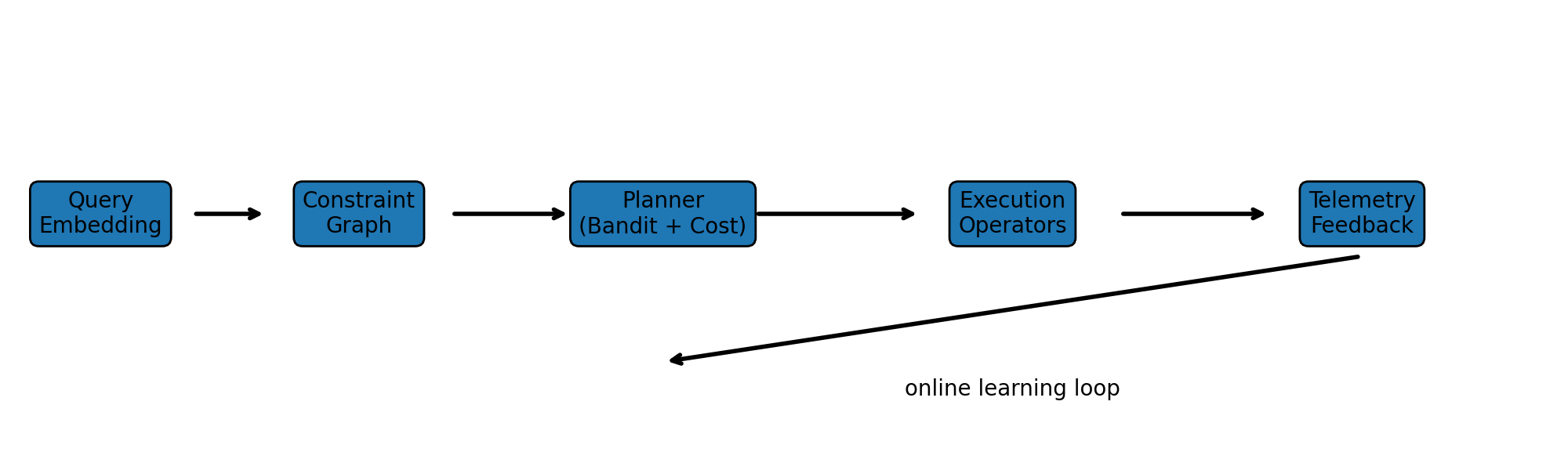
How do you decide which trick to use at each step? LLM-QP frames this as a contextual bandit problem — basically, a traffic controller that learns from experience. It looks at the current situation (how many tokens are valid, how confident the model is, how deep into the sequence we are) and picks the fastest execution plan that won’t sacrifice quality. Over time, it gets better at routing.
All of this plugs into existing ML compiler infrastructure (MLIR / StableHLO). The compiler generates multiple equivalent execution plans and selects the cheapest one at compile time or runtime. No new hardware required — it’s a software optimization layer on top of what already exists.
The Figures, Recomputed in Your Browser
The paper’s three benchmark figures were static images. Here they are again, computed live from the model’s own equations — drag the parameters and watch each claim hold or break. The contextual-bandit router is a real LinUCB instance learning in front of you.
Sparse scoring wins while K < |V|
Constrained decoding scores only the valid tokens. The dense head costs 2d|V| no matter what; the sparse head costs 2dK, where K is the number of legal tokens right now. Move the model dimension and vocabulary and watch the crossover sit exactly at K = |V|.
Amortize when the model is confident
If the top token is far ahead of the runner-up (a large margin), the next step probably has the same answer, so skip the full recompute. Refine only when the margin falls below the threshold τ. Drag τ: at τ = 0 the model trusts every step (cheapest, riskiest); at τ = 1 it refines always and collapses onto full recompute.
The router learns to route
A real LinUCB contextual bandit (Appendix A, running in your browser) sees each step’s context — how many tokens are valid, how confident the model is — and picks a plan. It is paid the true cost and updates. Watch cumulative regret against the hindsight oracle bend over and flatten: that bend is the convergence the paper claims, and nobody told the router the answer.
Deterministic given the seed. The router converges to within a few percent of the unbeatable oracle and leaves both fixed policies behind — and it learns that the conservative dense head is dominated, so it almost never picks it.
The original published run lives in papers/LLM-QP/*.csv; the live model agrees with it in shape, and that agreement is asserted in CI (model.test.js).
Faster Structured Output, Same Quality
Every time you ask an LLM to output JSON, fill a form, follow a schema, or generate code that compiles — that’s constrained decoding. It’s one of the most important capabilities for production AI systems, and it’s getting slower as models and vocabularies get bigger.
LLM-QP reframes this as a query planning problem — borrowed from database systems, where optimizers have spent decades learning to pick the cheapest execution plan that gives the same answer. The paper shows you can apply the same idea to LLM inference.
The result: equivalent outputs, less compute. No retraining, no new models, no hardware changes. Just smarter routing.